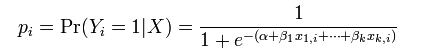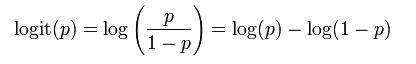����v�w�@VOL12�@��2�@�@2013�i�����j
* �@���̃R�[�X���w�ԏ��N�ցI
----------------------------------------------------------------------------------------stat12_t �@(�p�X���[�h�͎��ƒ������܂��B�jExercise�@stat12
sio satou syouyu jagaimo tamanegi beef oisisa
4 5 10 50 35 70 5
4 6 8 40 40 80 5
10 5 15 50 35 90 8
5 6 13 60 20 80 5
2 7 8 45 30 90 4
3 8 11 60 40 70 5
4 10 12 55 35 80 5
5 3 15 45 40 70 4
6 5 14 50 35 70 6
7 6 13 40 40 80 8
9 7 15 40 35 70 8
5 8 16 50 40 60 7
3 12 12 60 45 50 5
4 5 12 60 35 80 6
8 6 10 50 40 90 9
6 7 9 55 50 70 7
8 8 8 40 40 60 8
5 6 8 40 35 70 5
�Q�jRG�ɂ��̃f�[�^��C&P����B������2��ځ~1�s�ڂ�sio������悤�ɂ���
Loadings:
Factor1 Factor2 Factor3
col1sio 0.15 -0.52 0.31
col2satou -0.44 0.4 -0.12
col3syouyu 1
col4jagaimo 0.88 0.19
col5tamanegi -0.47 -0.12
col6beef 0.98 -0.13 -0.15
�Ō�̈ꉟ���I�I ���W�X�e�B�b�N��A���� �\�����ʂ� 0 ���� 1 �̊Ԃ����悤�ɁA�����₻�̑O��ɉ��ǂ��������Ă��� �B �\�����ʂ� 0 ���� 1 �̊Ԃ����悤�ɁA�����₻�̑O��ɉ��ǂ��������Ă��� �B ���̑���ɗp������̂��A���W�b�g�Ƃ������ɂ��ϐ��̕ϊ��ł��邱�Ƃ���A���W�X�e�B�b�N��A���͂ƌĂ��B���𗝉����邱�Ƃ������������Ȃ����A���͋C��͂�ł����K�v�����邾�낤�B ���W�X�e�B�b�N��A �i���W�X�e�B�b�N�������A�p : Logistic regression �j�́A�x���k�[�C���z �ɏ]���ϐ��̓��v�I��A ���f���̈��ł���B�A�����Ƃ������W�b�g ���g�p������ʉ����`���f�� (GLM) �̈��ł�����B���W�X�e�B�b�N��A�͈�w��Љ�Ȋw�ł悭�g����Bn �̃��j�b�g�Ƌ��ϓ� X ������A�ȉ��̂悤�ȊW�ɂ���B�I�b�Y �i1����m�������������̂Ŋm�����������l�j�̑ΐ��́A�����ϐ� Xi �̐��`���Ƃ��ă��f���������B��������̂悤�ɂ��\����B
�� �p�����[�^�̐�����I�b�Y�� �ɏd��ȉe��������B���ʂ̂悤��2�l�̐����ϐ��̏ꍇ�Ae�̃��� �͗Ⴆ�Βj���Ə����̌��ʂ��I�b�Y�� �̐���ł���B����ɂ��Ŗޖ@ ���g�����Ƃ������B���W�X�e�B�b�N��A���f���͒P���p�[�Z�v�g���� �Ɠ����ł���B
���̃��f���̊g���Ƃ��đ������ipolytomous�j���W�X�e�B�b�N��A������B�����J�e�S���̏]���ϐ��⏇���̂���]���ϐ��������B���W�X�e�B�b�N��A�ɂ��K�w�������������W�b�g ���f���ƌĂԁB
�Љ�Ȋw����ł̓T�^�I�ȉ��p�Ƃ��āA��Ƃ̉ߋ��̃f�[�^�����Ƃ��M�p���X�N �𐄒肷��Ƃ����p�@������B
2�l���W�X�e�B�b�N��A���_�C���N�g�}�[�P�e�B���O �ł悭�g���A�����Ăɔ�������l�X����肷��̂Ɏg����i�]���ϐ��́u��������=1�v�Ɓu�������Ȃ�=0�v�ł���j�B�_�C���N�g�}�[�P�e�B���O��2�l���W�X�e�B�b�N��A���f���́u���t�g�`���[�g�v���g���ĕ]�������B����́A�ߋ��̃��[���ւ̔����̃f�[�^�ƃ��f���ɂ��\�����ʂ��r����B
���W�X�e�B�b�N��A���f������ʉ����`���f�� �̈��ł���Bp (x ) ���A�\���l�ϐ� x �ɂ��Đ����̊m����\���Ƃ���ƁA���̂悤�ɕ\�����B
���W�b�g �iLogit�j�Ƃ́A0����1�̒l���Ƃ�p �ɑ�
�i�ΐ� �̒��1���傫����Ή��ł��悢�j
�ŕ\�����l�������B�ϐ� �Ƃ������W�b�g�� �Ƃ��Ă��B���W�b�g�������W�X�e�B�b�N�� ���t�� �ł��� �A�����m���_ �����v�w �ő����p������B
�m���_�A���v�w�ł� p �͂��鎖�ۂ��m�� ���Ӗ����A�u�m��p �̃��W�b�g�v�Ƃ���������������Bp /�i1 - p �j���I�b�Y �ɁA���W�b�g�̓I�b�Y�̑ΐ��ɓ�����A2�̊m���̃��W�b�g�̍����I�b�Y�� �̑ΐ��ɓ�����B
���W�b�g�͓��v�w�ŁA�������W�b�g���f�� �Ƃ��Ă悭�p������B���W�b�g���f���̍ł��P���Ȃ��̂�
���f���̓��Ă͂܂�̊m�F----�����
�Ԓr���ʋK�� �i�����������傤�ق���傤�������; ���X�� An Information Criterion, �̂��� Akaike's Information Criterion�ƌĂ��悤�ɂȂ�j�́A���v���f���̗ǂ���]�����邽�߂̎w�W�ł���B�P�� AIC �Ƃ��Ă�A���̌Ăѕ��̂ق�����ʓI�ł���B���v�w �̐��E�ł͔��ɗL���Ȏw�W�ł���A�����̓��v�\�t�g�ɔ�����Ă���B�����v���������� �������Ԓr�O�� ��1971�N�ɍl�Ă�1973�N�ɔ��\�����B
AIC�́A�u���f���̕��G���ƁA�f�[�^�Ƃ̓K���x�Ƃ̃o�����X�����v���߂Ɏg�p�����B�Ⴆ�A���鑪��f�[�^�v�I�ɐ������郂�f�����쐬���邱�Ƃ��l����B���̏ꍇ�A�p�����[�^ �̐��⎟���𑝂₹�Α��₷�قǁA���̑���f�[�^�Ƃ̓K���x�����߂邱�Ƃ��ł���B�������A���̔��ʁA�m�C�Y�Ȃǂ̋����I�ȁi����Ώۂ̍\���Ɩ��W�ȁj�ϓ��ɂ������ɂ��킹�Ă��܂����߁A����̃f�[�^�ɂ͍���Ȃ��Ȃ�i�ߓK�� ���AOverfitting�j�B���̖��������ɂ́A���f�����̃p�����[�^����}����K�v�����邪�A���ۂɂǂ̐��ɗ}���邩�͓�����ł���BAIC�́A���̖��Ɉ�̉���^����B��̓I�ɂ�AIC�ŏ��̃��f����I������A�����̏ꍇ�A�ǂ����f�����I���ł���B
�����͎��̒ʂ�ł���B
���ɂ�����ʂ���Ă���Ă��邪�A��{�Ƃ��Ă͂����܂Œm���Ă����Ηǂ��B �i����ȏ�̒m���ɂ��Ēm�肽���l�͏���ʂƃO�O���Ă݂ĉ������B�j ��������@�͎��ƂŃf�����X�g���[�V�������܂��B�����āA�������Ă݂悤�I
NO
sio
satou
syouyu
jagaimo
tamanegi
beef
repeat
1
4
5
10
50
35
70
0
2
4
6
8
40
40
80
1
3
10
5
15
50
35
90
1
4
5
6
13
60
20
80
0
5
2
7
8
45
30
90
0
6
3
8
11
60
40
70
1
7
4
10
12
55
35
80
0
8
5
3
15
45
40
70
1
9
6
5
14
50
35
70
1
10
7
6
13
40
40
80
1
11
9
7
15
40
35
70
0
12
5
8
16
50
40
60
1
13
3
12
12
60
45
50
1
14
4
5
12
60
35
80
0
15
8
6
10
50
40
90
1
16
6
7
9
55
50
70
1
17
8
8
8
40
40
60
1
18
5
6
8
40
35
70
0
19
4
5
10
50
35
70
0
20
4
6
8
40
40
80
0
21
10
5
15
50
35
90
1
22
5
6
13
60
20
80
0
23
2
7
8
45
30
90
0
24
3
8
11
60
40
70
0
25
4
10
12
55
35
80
0
26
5
3
15
45
40
70
0
27
6
5
14
50
35
70
1
28
7
6
13
40
40
80
1
29
9
7
15
40
35
70
1
30
5
8
16
50
40
60
1
31
3
12
12
60
45
50
0
32
4
5
12
60
35
80
1
33
8
6
10
50
40
90
1
34
6
7
9
55
50
70
1
35
8
8
8
40
40
60
1
36
5
6
8
40
35
70
0
37
5
6
13
60
20
80
0
38
2
7
8
45
30
90
0
39
3
8
11
60
40
70
1
40
4
10
12
55
35
80
0
41
5
3
15
45
40
70
1
42
6
5
14
50
35
70
1
43
3
12
12
60
45
50
1
44
4
5
12
60
35
80
1
45
8
6
10
50
40
90
1
46
4
10
12
55
35
80
0
47
5
3
15
45
40
70
1
48
6
5
14
50
35
70
1
49
3
12
12
60
45
50
1
50
4
5
12
60
35
80
1
stattest121
NO
UP_GO
10mws
MENTAL
MMT
balance
dualtask
tenntou
1
5
4
15
5
3
4
0
2
6
4
14
5
1
1
0
3
5
10
15
5
2
1
1
4
6
5
16
2
2
2
1
5
7
2
14
4
1
1
0
6
8
3
16
5
2
2
0
7
10
4
15
4
2
2
0
8
3
5
15
3
2
1
0
9
5
6
15
4
3
3
0
10
6
7
14
2
1
1
1
11
7
9
14
3
4
4
0
12
8
5
15
4
4
4
0
13
12
3
16
2
2
1
1
14
5
4
16
5
3
3
0
15
6
8
15
3
1
1
0
16
7
6
15
3
2
1
1
17
8
8
14
2
2
1
1
18
6
5
14
3
2
1
1
19
5
4
14
2
2
2
1
20
6
4
14
3
3
3
1
21
5
10
15
4
3
4
0
22
6
5
16
2
1
1
1
23
7
2
14
2
2
1
1
24
8
3
16
3
2
2
0
25
10
4
15
4
2
2
0
26
3
5
14
2
3
3
1
27
5
6
15
4
4
4
0
28
6
7
14
3
1
1
1
29
7
9
14
2
2
1
1
30
8
5
15
3
2
2
1
31
12
3
16
2
2
1
1
32
5
4
16
3
1
1
1
33
6
8
50
40
2
1
1
34
7
6
55
50
1
1
1
35
8
8
40
40
2
2
1
36
6
5
40
35
1
1
1
37
6
5
60
20
2
1
1
38
7
2
45
30
2
2
1
39
8
3
60
40
3
3
0
40
10
4
55
35
2
3
1
41
3
5
45
40
2
1
1
42
5
6
50
35
4
4
0
43
12
3
60
45
2
1
1
44
5
4
60
35
2
1
1
45
6
8
50
40
2
2
1
46
10
4
55
35
3
3
0
47
3
5
45
40
2
1
1
48
5
6
50
35
3
4
0
49
12
3
60
45
3
4
0
50
5
4
60
35
2
4
0
GO AGENDA
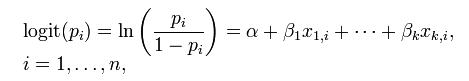 �ƕ\�����B
�ƕ\�����B