医療統計学 VOL10(ver.3)
学習項目(シラバスは講義題目と記しています)
相関係数と回帰式
講義内容と学習到達目標
1. Rまたはopen.calcを用いて あらかじめ用意されたデータについて相関係数と回帰式を求めることができること
2. 相関係数と回帰式の説明がヒントのある文章の中で説明できるようになること
3. 回帰直線に及ぼすバイアスの影響(交絡要因)を説明することができるようになること(オプション)
+++++++++++++++++++++++++++++++++++++++++++++++++++++++
可能ならば、理解して欲しいこと
・最小二乗法による相関係数の求め方の仕組み
・相関係数を求め、決定係数が分かると、さまざまな未知なデータに対してルールを基に推定が可能になること
++++++++++++++++++++++++++++++++++++++++++++++++++++++++
キーワード:最小二乗法・分散・相関係数・回帰式・決定係数・ノンパラメトリック
since 2014 医療統計学 相関関係
課題
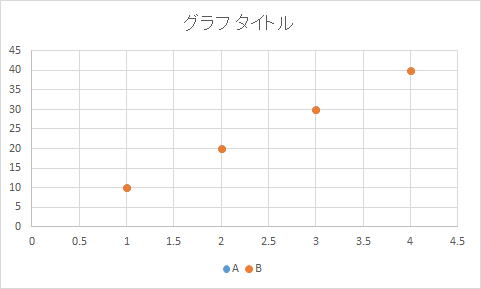
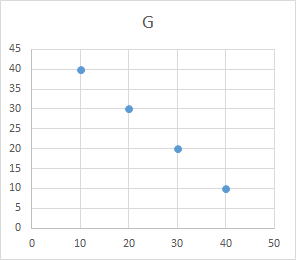
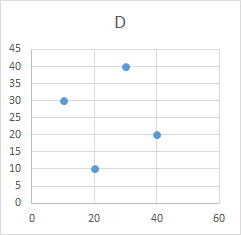
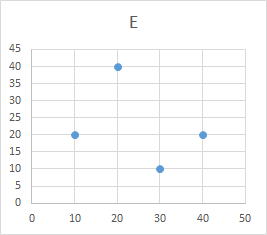
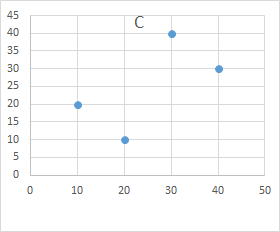
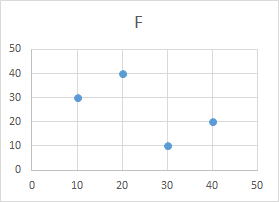
| 科目 | A | B | C | D | E | F | G | 科目 | A | G | 科目 | A | D | 科目 | A | E | 科目 | A | C | 科目 | A | F | |||||
| 学生a | 10 | 10 | 20 | 30 | 20 | 30 | 40 | 学生a | 10 | 40 | 学生a | 10 | 30 | 学生a | 10 | 20 | 学生a | 10 | 20 | 学生a | 10 | 30 | |||||
| 学生b | 20 | 20 | 10 | 10 | 40 | 40 | 30 | 学生b | 20 | 30 | 学生b | 20 | 10 | 学生b | 20 | 40 | 学生b | 20 | 10 | 学生b | 20 | 40 | |||||
| 学生c | 30 | 30 | 40 | 40 | 10 | 10 | 20 | 学生c | 30 | 20 | 学生c | 30 | 40 | 学生c | 30 | 10 | 学生c | 30 | 40 | 学生c | 30 | 10 | |||||
| 学生d | 40 | 40 | 30 | 20 | 20 | 20 | 10 | 学生d | 40 | 10 | 学生d | 40 | 20 | 学生d | 40 | 20 | 学生d | 40 | 30 | 学生d | 40 | 20 | |||||
| 科目 | 学生a | 学生b | 学生c | 学生d | |||||||||||||||||||||||
| A | 10 | 20 | 30 | 40 | |||||||||||||||||||||||
| B | 10 | 20 | 30 | 40 |
| Xi | xiーxm | (xi-xm)^2 | yi | yiーym | (yi-ym)^2 | (xiーxm)(yi-ym) | |
| 科目Aの成績 | 偏差 | 偏差の2乗 | 科目Aの成績 | 偏差 | 偏差の2乗 | ||
| 10 | -15 | 225 | 10 | -15 | 225 | 225 | |
| 20 | -5 | 25 | 20 | -5 | 25 | 25 | |
| 30 | 5 | 25 | 30 | 5 | 25 | 25 | |
| 40 | 15 | 225 | 40 | 15 | 225 | 225 | |
| 計 | 100 | 0 | 500 | 100 | 0 | 500 | 500 |
| 平均 | 25=xm | 25=ym | |||||
| Σ(xiーxm)^2 | Σ(yiーym)^2 | Σ(xiーxm)(yiーym) | |||||
| r=Σ(xiーxm)(yiーym)/√Σ(xiーxm)^2×Σ(yiーym)^2 |
相関係数=総和÷積和
-----------------------------------------------------------------------kimuakistatによる説明---------------------------------
最小二乗法による相関係数の求め方の仕組みの説明
(これは覚えられないと思うので、コンピュータがこういうことをやっているんだ、ということを知っておけばよろしい)
2群のデータの関係をみつけたいと思ったら、相関を調べたり(相関係数を求めると言います)、回帰分析を行います。
回帰式を作る作業を通して、最終的に2群のデータの関係をプロットした図においてデータの位置関係を一つの直線(あるいは曲線)で表すことが回帰分析です。
このとき、観測値のバラツキを最小限に抑える直線を決めるのが、相関係数や回帰式を求める上で必須なことになります。
この直線で求められる理論値と各々のデータの差、すなわち距離(差分)を二乗して、全部足し合わせた値が最も小さくなっている直線を回帰直線と呼びます。
この直線は一次方程式で表すことができるので、直線の傾きを決める係数と定数項が求められれば、決定することができます。
この係数と定数項は、横軸をx軸、縦軸をy軸とした場合、y=ax+ bとすると、aが係数、bが定数項となります。
ここで観測値のx軸上の平均値を求め、各々のデータとの差を計算した値を二乗し、全部足し合わせた数を総和とあらわすことにします。
この観測値の総和と同じようにy軸上の平均値を求めます。そして、その総和を求めます。
ここで、aの求め方が一気に、分かります。
このx軸上の総和を分母にして、分子に繰り返し登場しますがx軸の総和とy軸上の総和を掛け合わせたものが、a、すなわち直線の傾きになります。
定数項はaに対してx軸上の平均からy軸上の平均を引いた値を掛け合わせたもの、です。
相関係数は、x軸の総和とy軸上の総和を掛け合わせた数値の平方根を分母にして、k軸の総和とy軸の総和を掛けた値を分子において計算した値ということになります。
決定係数はこの相関係数を二乗したもの、ということです。
注意!この説明は、数式をただ言葉にして表したもので、仕組み(数式の成り立ち=中身)を説明しているに過ぎません。
概念を説明することは、また別です。すなわち、どういう意味があるのか=外見の説明、他の事柄との関係性=どんなことに使えるのか)という語り口の説明とは別のものです。
さて、相関係数とは・・2群のデータの関係の強さを表す数値のこと、-1から1の範囲でデータ間の構造と力を表すことができる、と言う具合に把握しておいてください。
回帰式とは・・従属変数を説明変数で表す方程式のこと、と言えます。
相関係数の二乗は、決定係数といいR2(この2は小さく右肩)(アールニジョウ)と表し、従属変数が説明変数を推定する程度を示しています。
R2=0.7というのは説明変数で推定した理論値と、実際の観測値が70%一致しているということ(残りの30%は残念ながらはずれ)を表します。
また、この理論値(推定値)<従属変数と実測値(観測値)<目的変数の差を残差と呼びます。
この残差が最小になる直線が最小二乗法による回帰直線といわれるものだったのです。(ああ、なんだそうか!)
以上・・・ああ、疲れるねい!(きむあき)
---------------------------------------------------------------------------------------------------------------------------
実は、影絵 のイメージが大切なんだな!
2群のデータの関係を一つの直線で表そうなんてことは、そう簡単には行かない。
そこで、暗闇の中でグラフに置かれた個々のデータが小さなボールにみたててみましょう。
ここでx・y軸に向かって垂直なビーム光を浴びせてみましょう(焼夷弾のようだ!)。
するとそれぞれの軸上のスクリーンに、ボールの影が映し出されるでしょう。
この影の位置は、それぞれのボールがもつx軸、y軸の値そのものといえます。
相関係数とか回帰式の係数と定数項というというのは、この組み合わせ(もしくは強引に)x軸とy軸のデータ間、あるいはデータ内の数値を足したり、割ったり、掛けたり、引いたりしているだけだということですね。
この計算の仕方を編み出した人に感謝しつつ、僕たちは、この考え方を利用させていただきましょう。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
statwork10
1. officeopen.orgを立ち上げopen.calcを開く。
2. データ1をコピー&ペーストする。
3. 2列のデータ群を選択し、散布図グラフを描く。
4. 散布図グラフ上の2列のデータの関係をあらわす回帰式を求める。
5. 2列のデータの相関係数を求める(関数コマンドから、この処理を行うコマンドをみつける)。
6. B列30行(B30)の右横、C30に回帰式を実行する数式を打ち出させる(データプロットをクリックするとウィンドウが出現する)。
7. いくつか、列B列にないデータをB30に入力し、C30の変化を観察する(楽しむ)
課題のデータはコレ!
| Strength | Distance/5s | |
| 1 | 55 | 16 |
| 2 | 35 | 8.8 |
| 3 | 42 | 10 |
| 4 | 36 | 9 |
| 5 | 30 | 7.8 |
| 6 | 50 | 14 |
| 7 | 33 | 8.6 |
| 8 | 38 | 9.6 |
| 9 | 45 | 12.2 |
| 10 | 42 | 12.5 |
| 11 | 35 | 8.9 |
| 12 | 58 | 16 |
| 13 | 53 | 14.4 |
| 14 | 33 | 8.5 |
| 15 | 48 | 13.6 |
<
*******************************************************************
アドバイス!
授業で相関係数と回帰式を求めたが、なぜこのような数値が2群のデータの関係を表すのか?理解したいと思ったら、
アイスクリーム統計学のサイトに入って、散布図、相関、回帰まで演習するといいでしょう。
ただし、ここではエクセルを使っていますが、open.calcでもほぼ同じことができます。
補足:決定係数は0-1の値をとります<必ず相関係数を2乗しているからです。
しかし、相関係数は-1から1の範囲の値をとります<マイナスがついている場合は、右下がりの直線で2群のデータの関係がまとまっている場合を表し、プラス(通常は+は付かない)の場合は、右上がりの直線で2群のデータの関係がまとまる場合を表します。)
相関係数の求め方を一度、その仕組みから理解しておきましょう。
相関と回帰を学ぶために!お知恵拝借!アイスクリーム統計学へ
回帰直線は
| 全情報 説明できている情報 失われた情報
回帰直線によって,全情報のうちどれくらい説明することができているのか その比を計算することにより評価することが可能です.そこで,その比のことを 決定係数 R2(decision coefficient)と呼び, |
と定義しました.
ここで,決定係数に着目し,少し式の変形を加えてみましょう.
回帰直線は,
式8.1
と表現されます. は,回帰直線上の値なので,上式は,
は,回帰直線上の値なので,上式は,
式8.2
となります.回帰直線の係数がややこしいので,
式8.3
とおくと,
式8.4
となりますから,決定係数は,
式8.5
と表すことができます.そして,この平方根をとった値,
式8.6
を 相関係数 R(correlation coefficient) と呼びます.これで,決定係数と相関係数の関係を理解することができます.すなわち,
式8.7
という関係が成り立っています.よく,教科書では,相関係数が定義されている場合が多いですが,「どうして,相関係数をそのように定義しているのか」疑問に思っていたのですが,上のような関係を考えますと,そのように定義した理由がよく理解されます.
|
R > 0 |
|---|
|
R < 0 |
|
R ~ 0 |
ここで,右のアプレットを見て下さい.5 回帰直線(1)と同じように扱います.このアプレットでは,決定係数だけではなく,相関係数も表示されています.10個の観測値を入力することにより,それに対する相関係数が分かります.いろいろな点を入力し,確かめてみることにしましょう.
いかがでしょうか? いろいろと試行しているうちに,グラフと相関係数の関係に着目すると,右のような場合に分類することができます.
● R > 0 のとき x と y は 正の相関を持つ
● R < 0 のとき x と y は 負の相関を持つ
● 相関係数のめやす
相関関係のめやすは一般的に以下のように表されます.
相関係数 相関関係 0.0~±0.2 ほとんど相関がない ±0.2~±0.4 やや相関がある ±0.4~±0.7 相関がある ±0.7~±0.9 強い相関がある ±0.9~±1.0 きわめて強い相関がある
相関係数のめやす
相関関係のめやすは一般的に以下のように表されます.
相関係数 相関関係 0.0~±0.2 ほとんど相関がない ±0.2~±0.4 やや相関がある ±0.4~±0.7 相関がある ±0.7~±0.9 強い相関がある ±0.9~±1.0 きわめて強い相関がある
おまけ
GLMについてメモ
一般線形モデルは従属変数が正規分布に従うと仮定されるものに限りますが、一般線形モデルを拡張した一般化線形モデルでは正規分布の他にポアソン分布や二項分布に従うデータについても解析することが可能。
| モデル名(モデル式) | 従属変数の数 | 従属変数の型 | 独立変数の数 | 独立変数の型 |
| 1要因分散分析モデル(Y1 = X1) | 1 | 連続型 | 1 | カテゴリカル型 |
| 2要因分散分析モデル(Y1 = X1 + X2 + X1*X2) | 1 | 連続型 | 2 | カテゴリカル型 |
| 単回帰モデル(Y1 = X1) | 1 | 連続型 | 1 | 連続型 |
| 重回帰モデル(Y1 = X1 + X2 + ... + Xn) | 1 | 連続型 | 2つ以上 | 連続型 |
| 共分散分析モデル(Y1 = X1 + X2) | 1 | 連続型 | 2 | カテゴリカル型と連続型 |
| 多変量分散分析モデル(Y1, Y2, ..., Yn = X1) | 2つ以上 | 連続型 | 1 | カテゴリカル型 |
一般化線形モデルに含まれるモデル:
| モデル名(モデル式) | 従属変数の数 | 従属変数の型 | 独立変数の数 | 独立変数の型 |
| ロジスティック回帰モデル | 1 | 2値データ | 1 | 連続型 |
| ポアソン回帰モデル | 1 | カテゴリカル型 | 2 | カテゴリカル型 |
モデル解析を行う際の注意
モデル解析を行う際には常に以下のことについて自問自答してみるとよいです。
オプション
交絡要因
回帰分析(参照pdf、立命館大 筒井先生)
GO AGENDA
 を用いて,得られた観測値と回帰直線の評価を行なうことが可能となります.すなわち,
を用いて,得られた観測値と回帰直線の評価を行なうことが可能となります.すなわち,









