このコースの目的
このコースの学習到達目標

アジェンダへ
ホームへ
stat001 Introduction Statistcs for Health Sciences
医療統計学入門 最初の1歩
このコースの目的
このコースの学習到達目標
*結果のプロセスが理解すること>結果のプロセスが理解できること

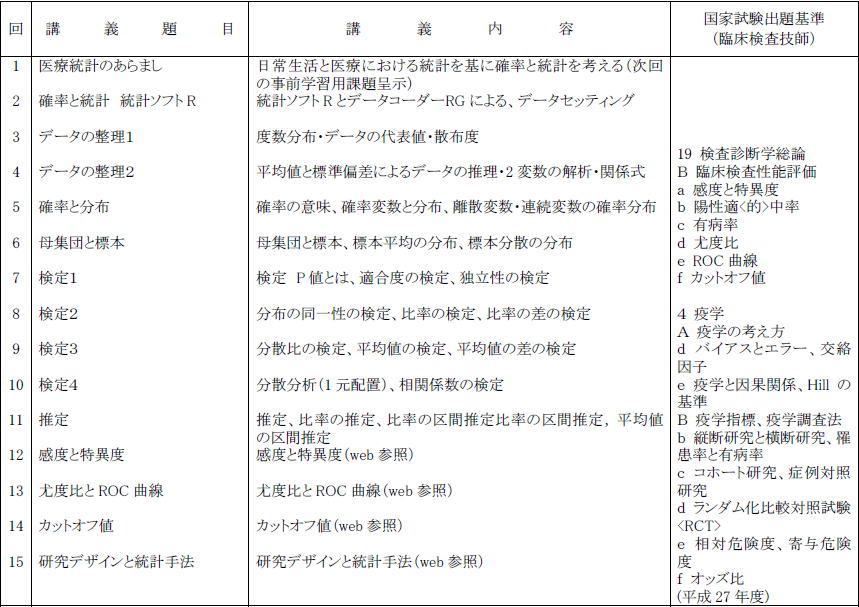
検査技術学科において関連する科目は以下

検査技術学科シラバスは以下
>腕試しに 確率と統計の基礎テスト
1.日常生活と医療における統計、その基になる確率、そして再び確率と統計を考える・・・
物事は定義から・・・

日常生活(にちじょうせいかつ)は、毎日繰り返される生活のこと。
具体的には、日々の生活の中で繰り返される出来事や習慣的動作、そこで用いられる物の考え方や知識(常識)、接する物品(その一部は日用品と呼ばれる)などから構成される。だが、その日常生活の内実を比較する時、歴史や文化に応じて、また個人によってもしばしば大きく異なる。自分の日常生活で当然であることが、他人の日常生活においては特別であったり、非常識であったりすることを知ることは、人に知的な驚きや教訓をもたらすことが多い。と同時に、余りにも異なる日常生活を送る人々の間に相通じる常識が見出されて驚きを誘うようなこともある。日常生活のパターンはそれが長続きするとしばしば伝統文化となる。また、時代の流れと共に移ろう風景や物の考え方や人々の心理は世相とも呼ばれる。
日々繰り返される物事の他にも、毎年繰り返される行事や伝統芸能、季節を特徴づける事物である風物詩なども、日常生活を理解する鍵として注目されることがある。
このような日常生活は、歴史学(とりわけ社会史)、文化人類学、民俗学、社会学、などの考察対象となる。
(出典 wikipedia http://ja.wikipedia.org/wiki/%E6%97%A5%E5%B8%B8%E7%94%9F%E6%B4%BB)
医療(いりょう、英語: medical treatment、health care)とは、人間の健康の維持、回復、促進などを目的とした諸活動について用いられる広範な意味を持った語である。
そもそも何が医療かということに関しては、「生物医学(biomedicine)的な根拠にのっとった近代医療のみを医療と見なす」という立場と、多元的医療システム観に基づき「その社会の一定程度の人に支持された、形式化された〈病・治療・健康〉をめぐる社会的文化的行為」とする立場に大きくわかれている[1]と黒田浩一郎は述べた。その意味では、補完医療、代替医療や伝統医療といった認識はあくまで近代医療をカウンターモデルとして構成されており、前者の立場の変形である[2]と池田光穂の著作では指摘されている。それらを総合したものは統合医療という呼称で呼ばれている。
(出典wikipedia http://ja.wikipedia.org/wiki/%E5%8C%BB%E7%99%82)
統計(とうけい)は、現象を調査することによって数量で把握すること、または、調査によって得られた数量データのことである。
統計の変遷
国家を統治するための基礎資料として活用されてきた歴史があり、建造物建設のための調査や兵役や徴税のための調査といったように、人口や土地等については古くから統計が取られている。
また、近代国家が成立した頃から政策の企画・立案のために利用されるようになり、それに伴い調査範囲も広がった。ナポレオン・ボナパルトは「統計は事物の予算である。そして予算なくしては公共の福祉も無い」と語り、1800年にはフランス、1828年にはオーストリアで国の調査機関が設立された。
日本の公的統計
日本の統計史
律令制における戸籍にその始まりを見ることができる。人口や土地面積等の把握は国家統治の基本であり、日本においても検地や人別改などとして歴代の国家主体・政治主体により実施されてきた。しかし、これらは調査方法が統一されていなかったり、調査・集計の体制が一貫していないなど、統計情報としての正確性に疑義がもたれるものであった。
調査方法を統一し、集計体制を整えたいわゆる近代的統計を日本で初めて実施したのは明治政府である。1871年(明治4年)太政官正院に「政表課」が設置され、近代的な統計制度が開始された。その後統計業務を行う組織は変遷したが、1885年(明治18年)の内閣制度成立とともに内閣統計局が発足し、以後終戦まで政府の統計業務を行うこととなる。
統計学(とうけいがく、英: Statistic、独: Statistik(ラテン語から、"statisticum (collegium)"), 本来の意味は: "社会の状態の科学”)とは、統計に関する研究を行う学問である。
統計学は、経験的に得られたバラツキのあるデータから、応用数学の手法を用いて数値上の性質や規則性あるいは不規則性を見いだす。統計的手法は、実験計画、データの要約や解釈を行う上での根拠を提供する学問であり、幅広い分野で応用されている。
英語で統計または統計学を statistics と言うが、語源はラテン語で「状態」を意味する statisticum であり、この言葉がイタリア語で「国家」を意味するようになり、国家の人力、財力等といった国勢データを比較検討する学問を意味するようになった。現在では、医学(疫学、EBM)、薬学、経済学、社会学、心理学、言語学など、自然科学・社会科学・人文科学の実証分析を伴う分野について、必須の学問となっている。また、統計学は哲学の一分科である科学哲学においても重要なひとつのトピックスになっている。これは、統計学が科学的な研究において方法論上の基礎的な部分を構成していながら、確率という一種捉えがたい概念を扱っているためであり、その意味や在り方が帰納の正当性の問題などと絡めて真剣に議論される。
統計的手法
歴史
統計学の源流は国家または社会全体における人口あるいは経済に関する調査(東西を問わず古代から行われている)にある。
学問としては、17世紀にはイギリスでウィリアム・ペティの『政治算術』などが著述され、その後の社会統計学に繋がる流れが始まった。また、ゴットフリート・ライプニッツやエドモンド・ハレーによる死亡統計の研究も行われた。これらの影響の基、18世紀にはドイツのジュースミルヒが『神の秩序』(1741年)で人口動態にみられる規則性を明らかにしたが、これには文字通り「神の秩序」を数学的に記述する意図があった。
ドイツでは17世紀からヨーロッパ各国の国状の比較研究が盛んになったが、1749年にアッヘンヴァルがこれにドイツ語で Statistik(「国家学」の意味)の名をつけている。19世紀初頭になるとこれに関して政治算術的なデータの収集と分析が重視されて、Statistikの語は特に「統計学」の意味に用いられ、さらにイギリスやフランスなどでも用いられるようになった。この頃アメリカ、イギリス、フランスなどで国勢調査も行われるようになる。
一方ブレーズ・パスカル、ピエール・ド・フェルマーに始まった確率論の研究がフランスを中心にして進み、19世紀初頭にはピエール=シモン・ラプラスによって一応の完成を見ていた。また、カール・フリードリヒ・ガウスによる誤差や正規分布についての研究も統計学発展の基礎となった。ラプラスも確率論の社会的な応用を考えたが、この考えを本格的に広めたのが「近代統計学の父」と呼ばれるアドルフ・ケトレーであった。彼は『人間について』(1835年)、『社会物理学』(1869年)などを著し、自由意志によってばらばらに動くように見える人間の行動も社会全体で平均すれば法則に従っている(「平均人」を中心に正規分布に従う)と考えた。ケトレーの仕事を契機として、19世紀半ば以降、社会統計学がドイツを中心に、特に経済学と密接な関係を持って発展する。代表的な人物にはアドルフ・ワグナー、エルンスト・エンゲル(エンゲル係数で有名)、ゲオルク・フォン・マイヤーがいる。またフローレンス・ナイチンゲールも、社会医学に統計学を応用した最初期の人物として知られる。
同じく19世紀半ばにチャールズ・ダーウィンの進化論が発表され、彼の従弟に当たるフランシス・ゴルトンは数量的側面から進化の研究に着手した。これは当時Biometrics*(生物測定学)と呼ばれ、多数の生物(ヒトも含めて)を対象として扱う統計学的側面を含んでいる。ゴルトンは回帰の発見で有名であるが、当初生物学的と思われたこの現象は一般の統計学的対象の解析でも重要であることが明らかとなる。ゴルトンの後継者となった数学者カール・ピアソンはこのような生物統計学をさらに数学的に発展させ(数理統計学)、19世紀終わりから20世紀にかけ記述統計学を大成する[1]。
20世紀に入ると、ウィリアム・ゴセット、続いてロナルド・フィッシャーが農学の実験計画法研究をきっかけとして数々の統計学的仮説検定法を編み出し、記述統計学から推計統計学の時代に移る。ここでは母集団から抽出された標本を基に、確率論を利用して逆に母集団を推定するという考え方がとられる。続いてイェジ・ネイマン、エゴン・ピアソンらによって現代の推計統計学の理論体系が構築され、これは社会科学、医学、工学、オペレーションズ・リサーチなどの様々な分野へ応用されることとなった。
こうして推計統計学は精緻な数学理論となった反面、応用には必ずしも適していないとの批判が常にあった。
これに呼応して、在来の客観確率を前提に置く統計学に対し主観確率を中心に据えたベイズ統計学が1950年代に提唱された。ベイズの定理に依拠する主観確率の考え方は母集団の前提を必要とせず不完全情報環境下での計算や原因の確率を語るなど、およそ在来統計学とは正反対の立場に立つため、その当時在来統計学派はベイズ統計学派のことを『ベイジアン』と名付けて激しく対立した。しかし主観確率には、新たに取得した情報によって確率を更新する機能が内包され、この点が大きな応用の道を開いた。今や統計学では世界的にベイズ統計学が主流となり、先端的応用分野ではもっぱらベイズ統計学が駆使されている。
計量経済学、統計物理学、バイオテクノロジー、疫学、機械学習、データマイニング、制御理論、インターネットなど、あらゆる分野でベイズ統計学は実学として活用されている。スパムメールフィルタや日本語入力の予測変換など身近な応用も数多い。20世紀末にはマルコフ連鎖モンテカルロ法など理論面で様々な革新的考案もなされ、旧来の統計学では不可能であったような各分野で多くの応用がなされるようになっている。これらベイズ統計学についての展開は、いずれも計算環境の進歩と不可分である。
一度信頼できる統計データが取れさえすれば統計学的分析は数学的に行えるが、信頼できる統計データの収集はとても難しい。実際、統計を取る人の主義主張によって統計値が大きく異なる事も多々あり、レーガン政権は当時アメリカにホームレスが30万人しかいないと主張したが、活動家達はその10倍の300万人いると主張した[2]。
例えば、質問の仕方一つで結果がガラリと変わってしまう。強姦に関するある調査で、女子大生に「男性からアルコールや薬物を飲まされて、望まない性交をした事がありますか」と質問する事で「女子大生の1/4が強姦された事がある」という結論を出したが、批判者達はこの調査で強姦体験者と認定された女子大生達を集めて再調査したところ、その3/4がその体験を強姦だと考えていないことが分かった[2]。
また、暗数の考慮にも主観がつきまとってしまう。暗数とは「統計に出ない値」のことで、例えば強姦のような犯罪はそれがタブーであるが故に警察に届けないことも多く、したがって統計に表れない。それには統計を正しく読み解くには暗数を考慮する必要があるが、統計値を多く見積もりたい人は意識的・無意識的に暗数を多く見積もってしまう可能性があり、逆に統計値を少なく見積もりたい人は暗数を少なく見積もってしまう可能性がある。
正しい統計データから正しい統計操作を行ってもなお騙すことが可能である。ここ四十数年で少年犯罪は1/4になっているが、「少年犯罪は急激に犯罪が増加している」ことを主張したければ、最近10年分のデータだけを提示すれば、最近10年分では微増しているため、その主張は成立することになる[3]。グラフの縦軸(=犯罪数の軸)をわざと縦長に書く事で犯罪数が急上昇しているように見せかけることも可能である。
統計学は「実学」に端を発しており、近代社会以降世界に普及した「市場経済社会」を牽引した原動力とも言える学問である。そのため、自然科学・社会科学・人文科学の各分野の垣根を越えて分化かつ拡大を続ける中、基礎において汎用性が高い学問の構造を有している。
日本においては「統計学科」を置く大学がない背景は、先述の通り、それぞれの分野へ分化された形で組み込まれているためである。
国立の統計学研究・教育機関としては、1944年に設立された統計数理研究所があり、AIC、数量化理論、確率微分方程式などの顕著な成果を生み出し、統計学研究を牽引している[4]。
社会生活の至る所で統計技術の適用が貢献できる場面がある以上、統計学とその適用方法を学習する上では社会の実態に即して頻繁に技法を適用してみることが重要であり、そのように出来るためには何よりまず統計処理を身近で制限無く実施できるような「統計処理環境」の備えが必要である。PC・ソフトウェア・インターネット環境などのIT環境が急速に進化低廉化して普及したことで身近に統計処理環境を持ちうるようになり、なおかつ莫大な統計情報がインターネットを通じて公開されているため、研究・調査・学習の処理材料にも不自由しない。
実際21世紀に入って以降は、それまでの確率論と数理統計学を重点に置いたカリキュラムに加え、データを処理して求める答えに近づく「データ解析」のスキルが教育されるようになっている。
元来コンピュータを使った数値計算に際してはまず、IEEE 754規格にあるように丸め誤差が暗黙のうちに生じることや、有効数字の概念の認識が重要で、子供のころ算数で学んだような計算結果にはならないことがあることを知っておかねばならない。さらに、統計計算では殊に重要な乱数についても、コンピュータ上で用いるのは疑似乱数であることや、良質な疑似乱数生成方式「メルセンヌ・ツイスタ」を計算ソフトウェアや開発用言語の全てが必ず備えているわけではないこと、暗号論的乱数はさらにまた別の乱数概念であること、なども実は大切な基礎知識である。
人が得意とするパターン認識の力を積極的に用いるため、統計データの「グラフ化」が古来常套手段として用いられているが、ITの支援を得ることで大量のデータを様々な形に、しかも瞬時にグラフ化(あるいは『見える化』)することが可能となった。そのためのグラフ作成ソフトも多数存在するが、その他の数値解析ソフトウェアや数式処理システム、そして殊に下記のような統計アプリケーションではグラフ化するための機能が充実している。一方、近年オフィスソフト機能等で極端なグラフ装飾を施すことが横行している。この結果として、例えば3Dグラフなどを安易に用いると遠近感や区間面積などから表示すべき真の数量とは異なった認識を受け手に与える事がある。本来3Dグラフ表示は人の空間認識力を活かし得る優れた表現手法であるが、意味なく勢い付け等で用いるのは本来的な視覚化からは退行するばかりか、意図して受け手の誤認識を誘導する事も可能となる。「グラフは直感的に分かるから全て善である」と一般に認識されていることや、前出「統計の困難さ」にある内容をふまえると、統計の視覚化とその解釈に関するリテラシ教育は初等段階から特に注意を要する。
上記のように、用いる統計処理環境ごとに適用分野・目的・方法論・使用者との相性などは異なる。そういった統計処理環境固有の特性なども含めて、いかなる道具もそうであるように、数多く体験の機会を作るほかに理解の早道は無い。
広く普及した表計算ソフトウェアが統計処理・グラフ表現機能を持っているので、誰でも手軽に統計処理入門体験は出来る。しかしあくまでビジネスソフトであり、科学技術ソフトではないExcelの計算の信頼性については常に批判が絶えない[5][6][7][8](Excelに限らず普及している表計算ソフトウェアはどれも信頼に足る統計計算はできないとの報告もある[9])。近年では研究・教育機関が公開するオープンソースなフリーソフトの中からきわめて優秀な計算ソフトウェアが育っており、プロプライエタリソフトの問題点顕在化により関心の高まった統計技術資産の持続可能性という観点からも、統計教育にあたってはこれらオープンソースソフトウェアの積極的な活用が推奨される。
統計の研究・教育に適した代表的なフリーソフトウェア
統計計算に関連するソフトウェアのカテゴリ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||