Kimuakistat2011 vol.11 オッズ比
新しい検査・測定方法を開発する時(された時)、その方法による臨床事象(現象)の推定能力(臨床推定能力)の優劣を判断するために必須の医療保健情報学の知識
>感度-特異度、尤度比、ベイズの定理、オッズ比、的中率
----------------------------------------------------------------------------------------
オッズとオッズ比 DL>stat11_odds
(パスワードは授業中に教示)
Exercise Stat11
----------------------------------------------------------------------------------------
医学における感度
(出典http://ja.wikipedia.org/wiki/%E6%84%9F%E5%BA%A6)
医学・保健学における感度とは、臨床検査(理学療法における検査も含まれる)の性格を決める指標の1つで、ある検査について「陽性と判定されるべきものを正しく陽性と判定する確率」として定義される値のこと。
感度が高い(高感度である)、とは、「陽性と判定されるべきものを正しく陽性と判定する可能性が高い」、あるいは「陽性と判定されるべきものを間違って陰性と判定する可能性が低い」という意味である。
感度と特異度
感度と対となる表現に特異度があり、特異度は感度との兼ね合いで決まる。
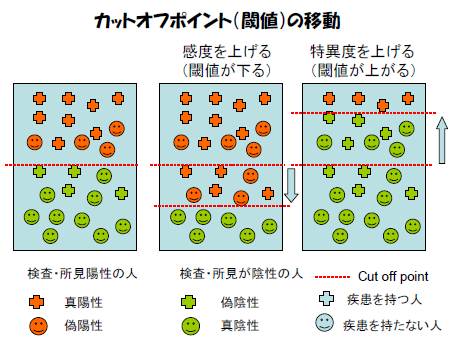
ある病気Aで血清中の値が上昇する酵素を考えるとする。この検査では正常人では平均100程度の数字であるが、病気Aを持っている者では平均1000程度の数字まで大幅に上昇する、と、統計的に分かっているとしよう。この場合、カットオフ値、つまり正常と異常の境目をどこにするのが妥当であろうか。
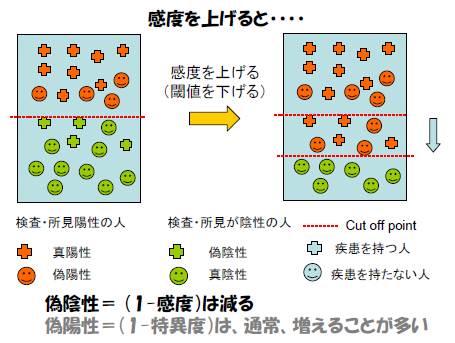
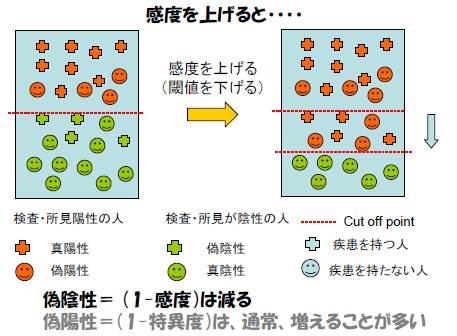
たとえば、150以上は異常、150未満では正常、として、この検査を運用するとする。すると、本当は病気Aではないのに「異常」と判定される被験者の数は必然的に増加する(偽陽性が増加する)。このような検査は、病気Aを持っている人を見逃す可能性は低いが、病気Aを持っていない人を正しく判定できる可能性は低い。つまり、高感度、低特異度の検査となる。
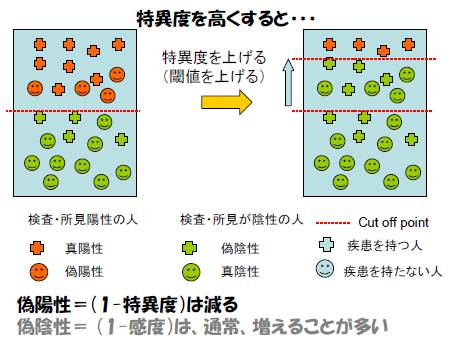
全く同じ検査でも、800以上は異常、800未満では正常、として、この検査を運用すると、今度は病気Aであるのに「正常」と判定される被験者の数が増える(偽陰性が増加する)。このような検査は、病気Aを持っていない人を不必要に心配させる可能性は低いが、病気Aを持っている人を正しく判定できない、低感度、高特異度の検査である。
理想の検査とは感度も特異度も完全に100%である検査であるが、実際にはそのような完璧な検査は存在しない。カットオフ値は、感度と特異度、両方の値を出来るだけ高くするよう適切な値に取るのが原則である。まず最初に、スクリーニング検査を行うが、これは安価な検査ながら感度を非常に高め、陽性の見逃しの可能性を極力減らし、特異度を犠牲にした検査を考えることが一般的であるからである(すなわち偽陽性が出やすい)。
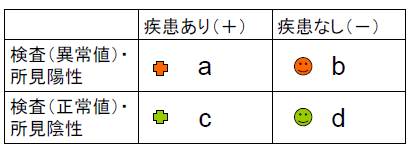
表1.症状・検査結果と疾患の有無
|
疾患(+) |
疾患(-) |
|
|
症状陽性 |
a |
b |
|
症状陰性 |
c |
d |
aからdは人数
感度 = (真)陽性率 = a/(a + c)
特異度 = (真)陰性率 = d/(b + d)
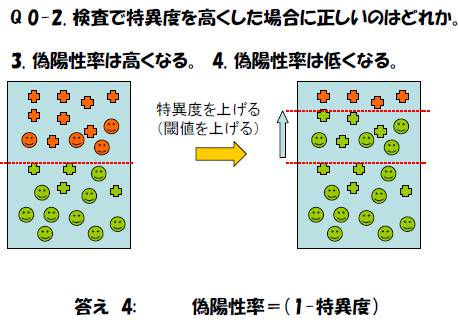
偽陽性率 = b/(b + d)
偽陰性率 = c/(a + c)
陽性尤度比 Likelihood ratio for a positive finding (LR+) =
陽性率/偽陽性率
= [a/(a + c)]/[b/(b + d)]
陰性尤度比 Likelihood ratio for a negative finding (LR-) =偽陰性率/特異度
= [c/(a + c)]/[d/(b + d)]
*陽性尤度比とはその所見が患者でどれ位陽性に出やすいかを表す指標となる。
理想は感度100%かつ特異度100%
医療統計学―保健医療情報学の基礎-感度-特異度とオッズ比
1.感度と特異度
感度とは?
感度:
陽性と判定されるべきものを正しく陽性と判定する割合
=その疾患を持った人のうち、その所見がある人の割合。
(「検出力の強さの指標」って感じ)
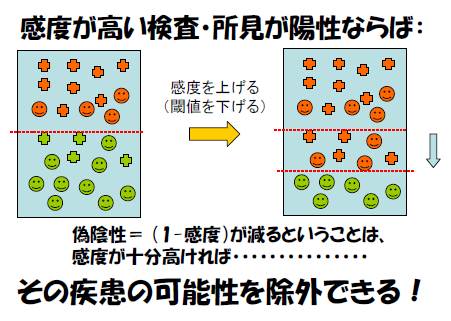
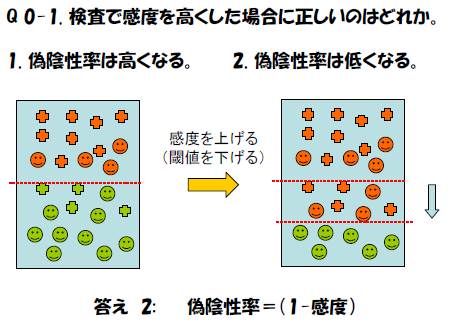
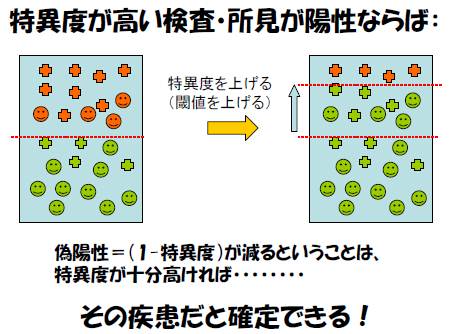
「感度が高い検査、所見」では:罹患者の見逃し(偽陰性)
は少なくなる。(逆に、通常は、偽陽性が増える)
感度が高い検査・所見が「陰性」ならば、その疾患を除外
(rule out) しやすい。
ひよこの雄雌の見分け方がいくつかあったとしよう。
その見分け方(検査法・ルール)の成績を統一ルールで比べることで優劣がはっきりする。
このような推論の正しさを見分ける方法に確率論を取り入れることで、より確からしさを増すことができる。
特異度とは?
特異度:
陰性と判定されるべきものを正しく陰性と判定する割合
=その疾患を持たない人のうち、その所見がない人の
割合。(「確実性」の指標って感じ)
「特異度が高い検査、所見」では:偽陽性(正常を異常と
判定)は減るが、通常、偽陰性は増える。
特異度が高い検査・所見が「陽性」ならば、その疾患を
確定(rule in)しやすい。
感度と特異度の関係
標本数=a+b+c+d
有病率(a+b)/ a+b+c+d
感度=a/(a+c) (真陽性率)
特異度=d/(b+d)(真陰性率)
偽陽性(false positive)率= b/(b+d) (1-特異度)
偽陰性(false negative)率= c/(a+c) (1-感度)
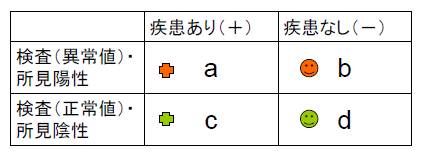
標本数=a+b+c+d
有病率(a+c)/ a+b+c+d
感度=a/(a+c) (真陽性率)
特異度=d/(b+d)(真陰性率)
偽陽性(false positive)率= b/(b+d) (1-特異度)
偽陰性(false negative)率= c/(a+c) (1-感度)



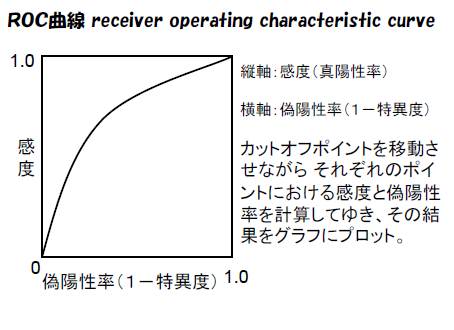
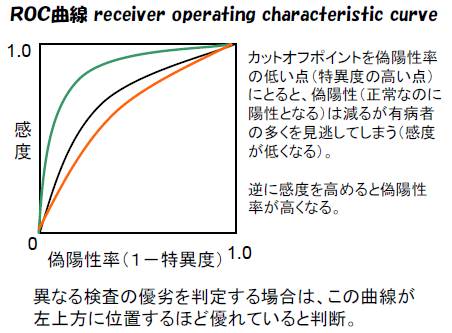
ROC曲線とは?

尤度比Likelihood ratio (LR)とは?
尤度比(陽性尤度比)=
有病者がその検査結果や所見を示す確率 /
無病者がその検査結果や所見を示す確率
= 真陽性率 / 偽陽性率
=感度 / (1-特異度)
陽性尤度比:それっぽさ
陰性尤度比:それっぽくなさは:
偽陰性率/ 真陰性率=(1-感度)/特異度
尤度比は、感度と特異度から算出できる!
尤度比、特異度、感度の関係
陽性尤度比= 感度/(1-特異度)
陰性尤度比= (1-感度)/特異度
ここで:(1-特異度)=偽陽性率
(1-感度) =偽陰性率
• 特異度100%の時、陽性尤度比は無限大
= 確定診断(Ruled in)
• 感度100%の時、陰性尤度比はゼロ
= その疾患を完全除外(Ruled out)
問題A
虫垂炎:感度と特異度からCT検査の尤度比を求める
CT検査:
感度90~100(95) %
特異度95~97(95)%
(検査のタイミングにもよりますが・・)
Am Fam Physician 1999;60:2027-34
解答
CT検査の感度と特異度から尤度比
CT検査:感度95%
特異度95%
感度=a/(a+c) =0.95;特異度=d/(b+d)=0.95。ここで、
所見があった時のそれらしさ(陽性尤度比)=
感度/(1-特異度) =0.95/(1-0.95)= 19.0
所見なしの時のそれらしくなさ(陰性尤度比) =
(1-感度)/特異度= (1-0.95) /0.95 = 0.05
虫垂炎のCT検査のEBMデータから尤度比算出
ベイズの定理
英語で奇数のことをオッズ、偶数のことはイーブンといいます。約分出来る間はイーブンですが、それ以上約分出来なくなった状態はオッズですね。
事前オッズx 尤度比= 事後オッズ
データにもとづいて事後確率を求める
• 発症率や罹患率によって事前確率がわかり、
検査や所見の尤度比がわかれば、ベイズの定理によって
事前オッズx 尤度比= 事後オッズ
事後オッズを確率に直すと、データにもとづいた事後確率(的中度)が得られる。(これをベイズの定理という)
オッズoddsとは?
「ある事象が起きる確率/ ある事象が起きない確率」
=「ある事象/それ以外の事象」
赤球2個、白球8個が入った箱から球を取り出す場合の赤球の出る
オッズは?
「ある事象が起きる確率/ ある事象が起きない確率」
赤球が出る確率は: 2/10 = 0.2
白球(赤球以外)が出る確率は: 8/10= 0.8 もしくは1-0.2=0.8
赤球が出るオッズは0.2/0.8 = 0.25 これは0.2/(1-(0.2))と同じ
「ある事象/それ以外の事象」(上の「分母」がキャンセルアウト):
赤球の出る事象=2
赤球以外が出る事象8
赤球が出るオッズは: 2/8 = 0.25 (当然ですが、上と同じ)
オッズodds(覚えるための整理)
確率とオッズの違いをマスターしよう。
確率=その事象/ 全事象
オッズ=ある事象が起きる確率/ ある事象が起きない確率
=ある事象/ それ以外の事象
ある事象が起きる確率をp、その事象のオッズをdとすると:
d = p / (1 - p)
d = 0.2/ (1-0.2) =0.2/0.8 = 0.25
ベイズの定理
事前オッズ x 尤度比= 事後オッズ
事前確率と尤度比から事後確率(的中度)が出せる
方法:(オッズをd、確率をp と置く)
1.事前確率をオッズに変換して事前オッズとする;
換算式:d=p / (1 - p)
2.事前オッズに尤度比を乗じて、事後オッズを求める:
事前オッズ X 尤度比=
事後オッズ
3.事後オッズを確率に変換して事後確率(的中度,p)を得る:
換算式: p=d / (d + 1)
問題1
CT検査の尤度比から事後確率を求める
CT検査:感度95 % 特異度95%
感度=a/(a+c)
=0.95;特異度=d/(b+d)=0.95。
所見があった時のそれらしさ(陽性尤度比)=
感度/(1-特異度) =0.95/(1-0.95)= 19.0
仮に、CT検査前の身体所見から推定した虫垂炎の事前
確率を20%とし、CT所見陽性の時の尤度比から事後確率
を計算してみる:
事前オッズx尤度比=事後オッズ
(20/80) x 19.0 =
4.75
事後オッズ->確率
4.75/(1+4.75) =
0.826 = 83%
問題2
事前確率が変わると変化するのは
どれか。
a 感度
b 特異度
c 的中度
d ROC曲線
e 偽陰性率
ヒント:ベイズの定理
問題3
ある疾患の検査前確率が20%であり、
その後の検査結果の尤度比が4の時、検査後確率はどれか。
A 5%
B 20%
C 24%
D 50%
e 80%
ヒント: 事前オッズx 尤度比=事後オッズであるので:
1.事前確率20/100をオッズに変換= 20/(100-20) = 20/80
2.事前オッズに尤度比を掛ける= 20/80 × 4 = 80/80 (事後オッズは1)
3.事後オッズを確率に変換1 /(1+1) =
問題4
60歳の男性。セカンドオピニオンを求めて来院した。検査データではCA19-9のみ上昇していた。CA19-9の膵癌検出の感度は50%、特異度は75%であり、この患者での膵癌の検査前確率を20%と仮定する。
CA19-9の上昇を考慮した検査後確率はどれか。
a 26%
b 33%
c 40%
d 47%
e 54%
陽性尤度比= 感度/(1-特異度) =0.50/(1-0.75)=2.0
事前オッズx 尤度比=事後オッズ;;
事後オッズを確率換算
(20/80) x 2.0 = 0.5 ;; 0.5/(1+0.5) = 0.333・・・
問題5
大腸癌に対して感度80%,特異度70%の検査がある。ある地区でこの検査を施行したところ、
100人の陽性者が見つかった。
真に大腸癌を有すると予測される人数はどれか。
a 20人
b 30人
c 70人
d 80人
e 予測できない
問題6
大腸癌に対して感度80%,特異度70%の検査がある。
ある地区でこの検査を施行したところ、100人の陽性者が見つかった。真に大腸癌を有すると予
測される人数はどれか。
a 20人
b 30人
c 70人
d 80人
e 予測できない
検査陰性c d
検査陽性a b
疾患+ 疾患-
考え方1:求める値がa+c
の時:
感度=a/(a+c) =0.8
特異度=d/(b+d)=0.7
a+b = 100 がわかっていても、
a+cの値は確定できない。
問題7 特異度が100%の時「真に大腸癌を有する」人数は何人か?
問題8 この調査で得られているはずの数値のうち、あと、何がわかれば「真に大腸癌を有する」人数が予測できるか?
医療統計学 11 kimuakistat11 advanced入門01
この単元のテーマ: サポートベクターマシン
この単元の副テーマ: 分布によらない事象への確率的推論(検定)
学習目標
1.サポートベクターマシンという計算機統計学のトピックを知ること
>知るために、どのような分野で具体的に活用されているか、供覧する。
2.回帰分析における標準化というテクニックを知っておく
3.分布によらない(不明な)データの集合に対する経験的確率の適応による、推定・検定テクニックを知ること
*ここで「知る」というのは説明できるということ。
---------------------------------------- kimuakistat
前説
サポートべクターマシンとは何か?
ベクターとはベクトルのこと、サポートとはベクトルの方向や力の源になっているもの(力を与えているもの)
マシンとはコンピュータがマシンであるということを指します。
分割線推定分析という、日本語が考えられています。
ここからは、kimuakistatに入って説明します。kimuakistat
---------------------------------------- kimuakistat
今日の課題
実践的統計解析時に良くある出来事を知っておこう、その対応方法を知っておこう。
1.回帰直線を求める場合に重要なデータの処理
2.2群のデータの平均値の比較がしたい>でもデータが正規分布していない>中央値を使う
この場合、t検定は使えない>そこで用いるのが・・・・検定
3.3群以上のデータの平均値を分散比を基に比較したい>でもでもデータが正規分布していない>中央値を使う
この場合、f検定は使えない>そこで用いるのが・・・・検定
---------------------------------------- kimuakistat
task11
1. データの標準化を行い、あらためてグラフを描き出し、相関係数や回帰式、直線を求めてみる
-------------------------------------------------------------------------------------------------------------------------------------
理学療法研究法-分布によらない検定(いわゆるノンパラメトリックデータの検定)
ここから後は、研究法の授業を取った人のみ、演習する課題です。
2. t検定を行ったデータ(変数)に対して、分布によらない検定を行う! 対応のあるt検定版がWilcoxonの符号順位和検定
2. t検定を行ったデータ(標本)に対して、分布によらない検定を行う! 対応のないt検定版がMann-Whitney検定
3. t検定を行ったデータ(標本)に対して、分布によらない検定を行う! 対応のない2標本t検定版がWelch検定
4. 1元配置分散分析(f検定)を行ったデータに対して、分布によらない検定を行う! Kruskal-Wallis検定
注:専門基礎の授業では2元配置分散分析は扱っていません。
5. 2元配置分散分析(f検定)を行ったデータに対して、分布によらない検定を行う! Friemanの検定
注意 2元配置分散分析では繰り返しありとなしの2通りの解析方法がある。この適応判断は、繰り返しなしを知っておけば、それ以外はすべて”あり”ということになるので、楽。
ルール:2元配置分散分析の繰り返しなしとは、すべての水準のデータが1つだけということ。ちょっとでも2回以上測っているデータを分析する場合は、繰り返しありという方法で行うべし。
6. 反復測定を伴うデータで分散分析する場合、同一検者の信頼性(あくまで統計学的な)もしくは同一測定機器の性能(再現性・安定性)を測定値のバラツキから知りたいと言う場合に良く用いられる!<注意、この分析こそ信頼性の評価そのものと考えている人がいるが、それはケースバイケースであるので、十分考えて使うこと、なぜなら人は学習するし、器械は磨耗する、あるいは生物は(物質はすべて・・・)時間の経過の中でdetriorationする>
kimuakistatの態度:許容される短時間もしくは短期間の(少なくとも半減期とかに至らない)性能を調べる場合に限定すべきである。
*これを応用すると、級内相関係数というものを計算することができる。
(時間もしくは回数の経過を一つの要因として考え、繰り返しのない2元配置分散分析の1要因の水準に回数を割り当てることで、計算する。)、
7. 順序尺度を扱ったとき、反復測定を行ったデータのバラツキを基に、検者間もしくは測定機器の一致率(安定性、あるいは巷で信頼性と呼ばれているもの)を検定する方法がカッパ係数分析である。
(これらはすべてRで算出可能。RGでは2から4まで可能である。)
-------------------------------------------------------------------------------------------------------------------------
stat10の課題では筋力と5秒間の最大歩行距離を調べていました。
しかし、筋力はftb(回転トルクのモーメント値(ftb、kgN)であったり、単純にある部位にかかる力(kg)、そして今回扱ったデータの範囲は30kg~55kgと25kgの範囲に収まっていました。
それに対して5秒間歩行距離と言うのはm(メートル、小数点1位まで)でした。そのデータの範囲は8m~13mと5mの範囲に収まっていました。
単位を無視しても25 対 5 =5:1 となっており、筋力が2倍になっても実際の歩行距離が2倍になるわけではないようです。
ここで、このような単位の影響を受けないようにして分析する便利な方法があります。
それを標準化といいます。
.
単位は標準偏差に影響を与えます。標準偏差はあるデータがその平均値の周りにどのくらいの幅で散乱しているいるかを示しています。 単位のとり方によって影響を受けるため、ごまかされてしまうことが良くあります。位取りの二乗の影響があることを覚えておいて下さい。
--------------------------------------------------------------------------------------------------------------------------
課題1
open.calcを使い、stat10の課題のデータに対して標準化して相関係数と回帰直線、回帰式を求めてください。
TIPS
標準化の方法:
超重要!!!
標準化された個々のデータ=(元のデータ - 平均値) ÷ 標準偏差
この式にしたがって、
この知識の意義: これを行えばほぼ世の中のすべてのデータの相関関係を正しく求めることができる!(大げさのようだけど、本当です。)
具体的なやり方:
課題2
RとRGを使って、分布によらない2群のデータの差(これは中央値が同じか否かを調べるものです)を以前のstat07の課題を使って検定してください。